From 2022 to 2024, with the successive advent of ChatGPT and DeepSeek, Generative Artificial Intelligence (Gen AI), with its superior learning ability and powerful capabilities in content creation, task automation, and decision optimization, has developed rapidly and covered many fields including creative content and media, digital marketing and e-commerce, education, financial services, healthcare, software development, industrial manufacturing and R & D, games and entertainment.
At the beginning of 2026, OpenClaw, also known as "Lobster" - an open-source AI agent tool, has further deeply expanded the focus of artificial intelligence from perceptual intelligence to generative intelligence. While relying on technological advantages to provide services to the market and achieve their own development, Gen AI service providers should not ignore the potential compliance risks brought by the technical output of content due to the core operation mechanism of Gen AI itself during the service provision and operation process for Artificial Intelligence Generated Content (AIGC).
Among these, data security and personal information protection, as key areas of enterprise compliance construction that have received much attention in recent years, combined with the key role that data plays in the underlying technical principle of Gen AI, have brought new challenges to Gen AI service providers in terms of relevant compliance risks and responses.
I. Legislative Situation
Different from the EU's Artificial Intelligence Act, which covers an overall framework legislation for artificial intelligence practices including prohibition provisions, general model obligations, confidentiality, and penalties, and Japan's Act on Promotion of Research and Development, and Utilization of Artificial Intelligence-related Technology passed last year, which only emphasizes that the government monitors the technology development trend, investigates abuse situations, and encourages relevant entities to comply voluntarily, the legislation in the field of artificial intelligence in China currently generally shows the characteristics of starting from national policy outlines, based on laws related to the network, data, and personal information, and conducting legal supervision and regulation in specific fields through special regulatory regulations, departmental rules, and national standards.
The Interim Measures for the Administration of Generative Artificial Intelligence Services (hereinafter referred to as the "Interim Measures") promulgated on July 13, 2023, as China's first special legislation for Gen AI, together with the earlier Regulations on the Administration of Algorithm Recommendations for Internet Information Services, the Regulations on the Administration of Deep Synthesis of Internet Information Services, and the Measures for the Identification of Artificial Intelligence Generated Synthetic Content (hereinafter referred to as the "Identification Measures") effective on September 1, 2025, jointly construct the embryonic form of China's AI supervision. And the upper-level laws including the Cybersecurity Law, the Data Security Law, the Personal Information Protection Law, and the Science and Technology Progress Law provide a more complete overall framework for the legal supervision of artificial intelligence in China.
In addition, according to the 2025 Legislative Work Plan announced by the Standing Committee of the National People's Congress, the legislative project for the healthy development of artificial intelligence is also among the preliminary review projects. Referring to the EU (which promulgated the world's first comprehensive artificial intelligence law - the Artificial Intelligence Act on June 13, 2024), it can be predicted that in the future, China is also likely to further introduce an overall and comprehensive law in the field of artificial intelligence within the existing legislative system framework.
Overall, the core points of the Interim Measures lie in its regulation of the technical definition, service scope, content type, and subject responsibilities of artificial intelligence, that is, "artificial intelligence technology" refers to models and related technologies with multi-modal content generation capabilities. These content types include text, pictures, audio, video, and the virtual scenes mentioned in the Identification Measures; the service scope is limited to providing generation services to the public within the territory of the People's Republic of China. The Interim Measures also clearly stipulate the relevant responsibilities of Gen AI subjects - service providers (hereinafter referred to as "providers") and service users (hereinafter referred to as "users"), especially the responsibilities of providers from the aspects of the R & D, operation, and optimization of Gen AI technology itself, as well as their responsibilities to users from the perspectives of network security and personal information protection.
In fact, two notable issues are raised in the above core points:
First, the regulatory object of the Interim Measures is the subjects that provide generation services to the public within the territory of the People's Republic of China, that is, overseas providers and users in non-public scenarios are not bound by this regulation. If an enterprise only uses Gen AI technology internally, it will not bear legal responsibilities under the Interim Measures. However, there is an obvious misunderstanding here, that is, the inapplicability of the Interim Measures does not mean that other laws related to artificial intelligence are also not applicable, especially when it comes to data security and personal information protection, they are applicable to all subjects involved in relevant legal regulation.
Second, the Interim Measures actually particularly emphasize the regulations that providers must abide by in the R & D training, optimization development of Gen AI, and the relationship with users, including the source of data, the collection of personal information, and the guarantee of data quality.
It can be seen that data and personal information are one of the key compliance issues that Gen AI providers must pay attention to. Therefore, clarifying the association between data and personal information and Gen AI is the starting point for enterprises to respond to relevant compliance risks from the perspectives of data security and personal information protection, and understanding the technical principle of Gen AI is an essential prerequisite.
II. Gen AI Technical Principle
1.Artificial Intelligence, Machine Learning, Deep Learning, and Gen AI
Before understanding the technical principle of Gen AI, it is necessary to position it in the entire technical landscape of artificial intelligence.
Artificial intelligence includes multiple branches, such as natural language processing, knowledge representation, automatic reasoning, computer vision, and robotics. These branches are interdependent and crossed. Machine Learning (ML) is one of the most widely applied branches, and its core is to let the machine automatically learn patterns or rules from data to make predictions or decisions. The main types include supervised learning, unsupervised learning, and reinforcement learning (these three types are also combined and used in AI model construction, such as semi-supervised learning that includes both supervised learning and unsupervised learning features).
Supervised learning refers to a machine learning method that is trained based on labeled data. By learning the mapping relationship from input to output, it makes predictions on new data. Simply put, it is to train the machine as a student with standard answers. Common application scenarios include speech recognition, face recognition, etc.
Unsupervised learning discovers data patterns from unlabeled data and performs operations such as classification, clustering (by means of data clusters to make the objects within the same cluster highly similar, for example, banks' clustering of abnormal transaction types can achieve anomaly detection), and dimensionality reduction (simplifying data while retaining key information, like reducing pixel data to enhance the speed of face recognition) on the data. In this situation, the output is not a preset answer but the internal grouping of the data. Common application scenarios include customer segmentation, recommendation systems, etc.
Reinforcement learning is a learning method based on reward signals. The agent optimizes its strategy in interaction with the environment by obtaining rewards or punishments to maximize long-term returns. Common application scenarios include autonomous driving, robot control, etc. The training framework OpenClawRL of "Lobster" takes machine reinforcement learning as the core. It should be noted that although the technical basis of Gen AI is mainly unsupervised learning, it actually still integrates supervised learning for optimization, and at the same time, it conducts reinforcement learning according to the preferences of human users for its generated results.
Deep Learning (DL) is a powerful method of machine learning. It uses multi-layer neural networks to simulate the way the human brain processes information and conducts machine learning by automatically extracting features layer by layer. For example, in face recognition, organs are extracted from the concrete face, edge shape features are extracted from the organs, and then these edges are abstracted into pixels. Its core is unsupervised feature learning, that is, the selection process of features does not require human participation. Gen AI belongs to the generative model technology direction in deep learning and is the product of the advanced stage of deep learning development. It uses the generative model technology architecture to create brand-new content, rather than just identifying or classifying existing data.
It can be seen that Gen AI is a technical field in the artificial intelligence system with the core goal of content generation and creation, and its mainstream implementation highly depends on the support of the deep learning architecture. In the text generation field, the autoregressive models (AR) based on Transformer occupy a dominant position, and typical representatives include the GPT series, DeepSeek - R1, etc.; in the image and video synthesis aspect, diffusion models have replaced generative adversarial networks (GAN) as the mainstream technical solution, such as models like Stable Diffusion and Sora are all constructed based on this paradigm; the generation of painting - related content is mainly completed by diffusion models, and the text prompt encoding and semantic understanding links rely on the Transformer architecture to achieve; music creation takes Transformer and its variants as the core technical path and does not commonly use diffusion models. (See Figure - 1)
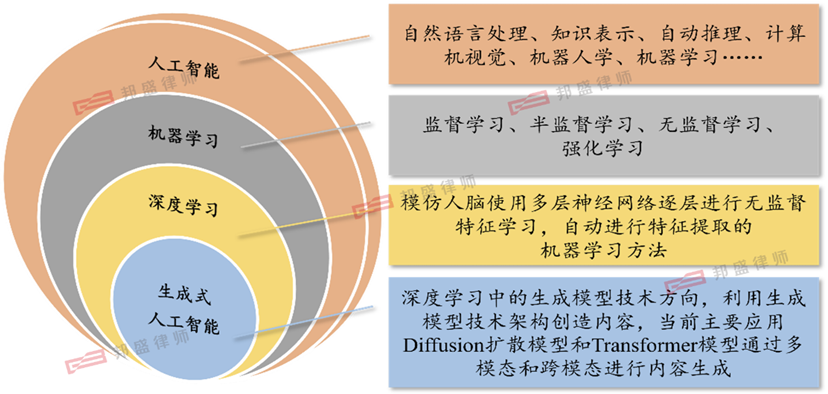
Figure - 1
Currently, the technical ecosystem of Gen AI is mainly driven by two core deep learning architectures, Transformer and diffusion models. As the key technical bases supporting content generation, the two form a typical collaborative paradigm in multi-modal scenarios. For example, in the "text-to-image" task, the Transformer - type model encodes and semantically models the text prompt, and then the diffusion model completes the image content generation according to the encoding information, so as to support the implementation of various generative artificial intelligence applications.
2.Gen AI Operation Principle and Data
One of the core features of artificial intelligence is "designed by humans, serving humans, essentially being computation, and having data as the foundation" [5]. The basis for it to provide generative content is to form valuable information flows and knowledge systems through the collection, processing, analysis, and mining of data. Therefore, the core ability of Gen AI comes from learning the essential laws and probability distributions of massive data, and then using the generative model to generate new data. The original material library used for learning may be tens of thousands of books or hundreds of millions of pictures. Through deep learning, the probability distribution characteristics of real-world data are identified and modeled (for example, the probability of "moon" after "raising my head to gaze at the bright [ ]" is much higher than "light").
Currently, the training process of mainstream Gen AI mainly includes two core stages: pre-training and supervised fine-tuning (SFT). The former is to complete the basic semantic understanding, knowledge representation, and general pattern modeling of the model through massive unlabeled text or multi-modal data using self-supervised learning methods, enabling the model to have basic language generation and content cognition capabilities. Based on this, SFT uses the pre-trained model as the initialization parameters and uses a small amount of high-quality labeled data to optimize the model in a targeted manner, making it suitable for specific task requirements, rather than building and training the model from scratch [6]. For example, by supervised fine-tuning on data related to legal provisions, judicial cases, and other related fields, the professionalism and accuracy of content generation and question answering in legal scenarios can be significantly improved.
It can be said that data is the lifeblood of Gen AI, the core production factor, and an important foundation for its technical operation, and the scale and quality of the training data directly determine the final effect of AIGC. The scale of data determines the diversity and model generalization ability of AIGC. The wider the coverage of the training data samples, the more refined the patterns of complex modalities such as text, language, and images that the model can capture; conversely, if the data diversity is insufficient, it is likely to exacerbate model bias and lead to significant deviations in the output results. For example, if 90% of financial cases in the training data occur in Shanghai, the model may learn an unreasonable correlation, and AIGC may generate incorrect inferences such as "financial cases must occur in Shanghai" that do not conform to objective reality.
In addition, the better the quality of the data, the higher the reliability of AIGC. If the signal-to-noise ratio (SNR) of the data source is low (when there is a large amount of error, false, or redundant information so that the useful information is "drowned"), it may lead to the model overfitting the noise, that is, wrongly learning non-essential associated features, and may trigger hallucinations, generating content that does not conform to the facts, such as non-existent legal provisions and cases.
Based on the above situation, in order to control the possible content biases and risks brought by AIGC, it is necessary to improve the data cleanliness. Specifically, it is to clean the data through pre-training corpus engineering such as deduplication (deleting duplicate content to prevent the model from mechanically copying) and toxicity filtering (removing illegal,and bad information to prevent the generation of harmful text).
III. The Compliance Significance of Data Security and Personal Information Protection for AIGC Service Providers
From the above brief description of the relevant principles of Gen AI and AIGC, it can be clearly seen that for Gen AI and AIGC, data plays a key and decisive role. The "Interim Measures" defines two roles from the perspective of AIGC research and development and use, that is, the provider and the user mentioned earlier.
According to the definition in the "Interim Measures", the provider is an organization or individual that uses Gen AI technology to provide Gen AI services (Including through providing programmable interfaces and other means, see Figure - 2). This definition actually includes two types of providers, namely Gen AI technology developers and service providers. The developer may directly provide services to the user, or may be integrated by the provider, and then the provider provides services to the user. In practice, relevant entities often do not play only a single role.
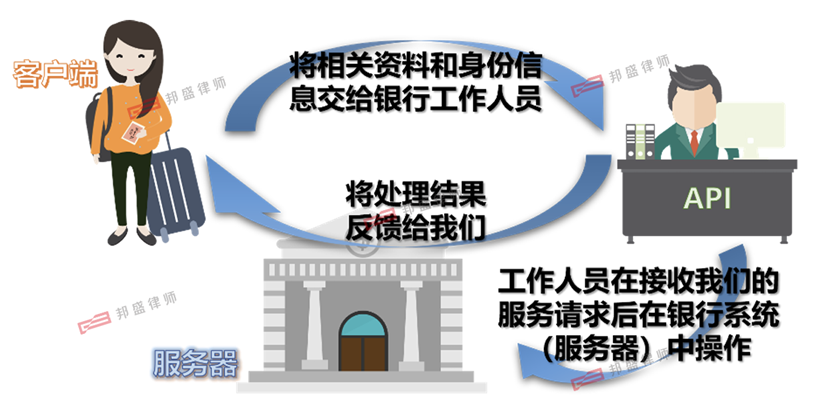
Figure - 2: Using the programmable interface API at the software level to analogize the customer's deposit and withdrawal business in the bank. During the API call process, the client (the customer with deposit and withdrawal needs) will send a request through the API (the bank staff), and the API will transfer the request (relevant identity materials, etc.) to the server (the bank system). After that, the server will process it according to the request, and finally return the processed response result to the client through the API.
In early 2023, the National Institute of Standards and Technology (NIST) under the US Department of Commerce released an "Artificial Intelligence Risk Management Framework" (Artificial Intelligence Risk Management Framework, AI RMF 1.0). This framework is not limited to generative artificial intelligence, but builds an AI life cycle model for the overall risk management of artificial intelligence-related technologies, including six dimensions: planning and design (Plan and Design), data collection and processing (Collect and Process Data), model architecture and use (Build and Use Model), verification and validation (Verify and 1 Validate), deployment and use (Deploy and Use), and operation and monitoring (Operate and Monitor) [1]. From the perspective of Gen AI, combined with China's legislative requirements, three stages of model training, application, and optimization should be focused on.
(I) Model Training
In the model training stage, the compliance key points for providers mainly involve two aspects: data source and data quality. The former emphasizes the legality of the data source, and the latter focuses on the authenticity, accuracy, objectivity, and diversity of the data.
1.Data Source
The data sources for training models currently mainly include self-collected data, open-source data, commercial training data, user input information, etc. [2] (see Figure - 3). Providers should pay attention to focusing on compliance risks and taking corresponding measures according to the different sources they use.
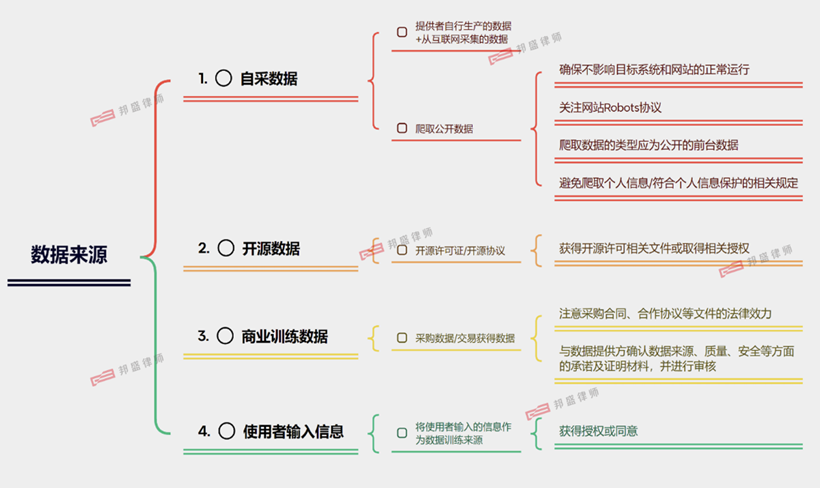
Figure - 3
1)Self-Collected Data. Self-collected data includes data produced by the provider itself and data collected from the Internet by itself. Crawling public data is one of the main ways of self-collected data and data training. In the process of automatically accessing and collecting public data on the Internet, if it involves breaking through the technical measures of the accessed target and successfully grabbing data, the provider needs to note: First, ensure that it does not affect the normal operation of the target system or website and control the access traffic and frequency; Second, pay attention to the website Robots protocol and do not bypass or crack the technical protection measures of the target website or system; Third, the type of data crawled should be public front-end data and should not be processed beyond a reasonable limit. When it involves personal information, it should be avoided; if it is indeed necessary to crawl, it needs to comply with the relevant regulations on personal information protection. Specifically, when general personal information is used as training data, the consent of the corresponding individual should be obtained and other relevant laws and administrative regulations should be complied with; when it involves sensitive personal information, the individual's separate consent should also be obtained.
2)Open-Source Data. Open-source data clarifies the conditions and restrictions for data use through open-source licenses (open-source agreements). Therefore, when using open-source training data, attention should be paid to the relevant content of the rights reserved by the licensor and the use boundaries of the licensee in the open-source license file of the data source.
3)Commercial Training Data. This type of data is purchased data. It is necessary to focus on the legal validity of purchase contracts, cooperation agreements, and other documents, and require the trading party or cooperation party to provide commitments and relevant certification materials on the data source, quality, safety, etc., and review these materials.
4)User Input Information. Users are usually To C end-users. Every input behavior of users to Gen AI - whether it is asking a question, amending a question, or issuing a specific processing task requirement - may contain the input of the user's own information data. Therefore, if the provider wants to use such information as training data, it needs to obtain the authorization of the user.
2.Data Quality
When this article discussed the operation principle of Gen AI in the previous article, it actually mentioned the importance of data quality for AIGC. Here, it will be further refined and analyzed from two aspects: data annotation and data training.
1)Data Annotation
Gen AI data annotation (Data Annotation) refers to the process of adding specific information such as labels, categories, or attributes to text, pictures, audio, video, or other data samples through manual operation or using automated technical mechanisms based on the corresponding information content of the prompt information [3]. The noise (Noise) generated by the inconsistency, bias, errors, etc. of data annotation will lead to the deviation of the model's learning and recognition of the data, resulting in hallucination phenomena in AIGC or the generation of unfair or discriminatory content.
Therefore, when it comes to data annotation, providers should pay attention to formulating annotation rules, including annotation objectives, data formats, annotation methods, quality indicators, etc.; clarify the specific types of annotation tasks, and determine task requirements for annotation tasks containing different contents such as text, pictures, audio, video, time series, etc.; formulate methods for 核验 the quality and safety of annotation results and emergency and handling mechanisms for security incidents. In addition, attention should be paid to conducting safety training for data annotators, clarifying the allocation of annotation tasks, and conducting effective personnel management.
2)Data Training
To avoid data value biases and a decrease in model credibility, providers should pay attention to ensuring the diversity and timeliness of training data. Through strict and meticulous data analysis and screening, ensure the representativeness of training data, and cover different fields, groups, levels, regions, cultures, etc. according to target needs. In addition, the trained data is not fixed. Providers should monitor and evaluate these data and adjust them in a timely manner to ensure that the data sources keep up with the latest developments in relevant fields and continuously improve the accuracy and reliability of AIGC.
3.Handling Core Data and Important Data
In addition to data sources and data quality, providers also need to pay extra attention to the handling of core data and important data. The "Data Security Law" has clear regulations on core data and important data, and the data classification and grading standards jointly issued by the State Administration for Market Regulation and the Standardization Administration of the People's Republic of China further provide a reference basis for data classification and grading from different perspectives [4].In addition, various industries and fields have successively issued regulations to clarify and refine the division of core data and important data in specific industries. For example, the "Administrative Measures for Data Security in the Industrial and Information Technology Field (for Trial Implementation)" classifies data in the industrial and information technology field into three levels: general data, important data, and core data according to the degree of harm caused to national security, public interests, or the legitimate rights and interests of individuals and organizations when the data is tampered with, damaged, leaked, or illegally obtained or used, and clarifies the specific division elements of the three levels of data. When Gen AI service providers conduct model training, if it involves the handling of core data and important data, they need to more strictly fulfill relevant obligations and accurately position the specific regulations and requirements of their industry.
(II) Model Application
In the model application stage, providers also need to pay attention to data security compliance obligations. Since it involves applications entering the To C end, the compliance focus in this stage will mainly be on personal information protection-related content, including the compliant processing of personal information, cross-border data transmission, and the protection of the rights of personal information subjects.
1.Personal Information Processing
According to the relevant regulations of the "Personal Information Protection Law", the processing of personal information should follow the principles of legality, legitimacy, necessity, and good faith, clarify the processing purpose, method, and scope, and adopt the method that has the least impact on personal rights and interests. In addition, special attention should be paid to the fact that if it involves the processing of sensitive personal information, the separate consent of such individuals must be obtained.
2.Cross-border Data Transmission
When Gen AI service providers deploy servers overseas, the data stored on the servers may involve cross-border data transmission. According to relevant laws and regulations, when an enterprise is a critical information infrastructure operator (CIIO) or the type and quantity of data processed reach the types and quantities specified by law, cross-border data transmission must be completed through specific compliance channels. The three compliance paths for data 出境 include passing the data 出境 security assessment organized by the national cyber affairs department, undergoing personal information protection certification by a professional institution, or concluding a contract with an overseas recipient in accordance with the standard contract formulated by the national cyber affairs department to stipulate the rights and obligations of both parties. Providers should complete relevant evaluation, approval, or declaration work according to the actual situation.
3.Protection of the Rights of Personal Information Subjects
The "Personal Information Protection Law" clearly stipulates the specific rights of individuals regarding the processing of their personal information, including the right to know, the right to make decisions, and the right to restrict or refuse others from processing their personal information; in addition, it also includes the rights to access, copy, correct, and supplement. Individuals have the right to request personal information processors to cooperate and assist in the exercise of these rights. Based on this, providers should ensure a full understanding of the protection of personal rights and ensure that individuals can fully exercise their legal rights, establish an effective communication and feedback mechanism, and promptly handle relevant requests from individuals.
(III) Model Optimization
In the model optimization stage, the most typical risk lies in the data collected through human-machine interaction being used for model iterative training. In practice, there have been cases where in the agreements signed between users and providers, users have clearly restricted the application of the data and related information obtained by providers from them, or directly prohibited their use for provider model optimization. Conversely, providers are also clearly indicating the processing methods of user data through the user agreements or privacy policies publicly available on the Gen AI service platform. In particular, providers need to clearly inform users that their data may be used for processing activities such as model iterative training and provide users with the convenience to give prior effective consent or refusal.
IV. Conclusion
This article, from the perspective of Gen AI service providers, takes data security and personal information protection as the starting point, and through the underlying operating principles of generative artificial intelligence, analyzes the compliance risks and responses that providers may face in Gen AI and AIGC. With the continuous improvement of laws and regulations in the field of artificial intelligence in China and the enrichment of judicial practice scenarios, the compliance obligations of enterprises in different roles in the development of artificial intelligence will also become clearer and more definite.
References
[1] Artificial Intelligence Risk Management Framework (AI RMF 1.0), [202604 - 15]https://www.nist.gov/itl/ai - risk - management - framework
[2] "Basic Requirements for the Security of Generative Artificial Intelligence Services in Cybersecurity Technology" (GBT45654 - 2025)
[3] "Security Specification for Data Annotation of Generative Artificial Intelligence in Cybersecurity Technology" (GBT45674 - 2025)
[4] "Rules for Data Classification and Grading in Data Security Technology" (GBT43697 - 2024)
Author: Zhang Yi
Source: Bangsheng Law FirmOriginal
Link:http://www.baclaw.com/41/787;http://www.baclaw.com/41/788
